In the C++Builder and RAD Studio 12.2 launch webinar, we made a big deal of having fast parallel builds on by default:

This blog is to provide some practical info on the feature.
Table of Contents
Using it
When you install 12.2, and use the Windows 64-bit Modern C++ platform, it is on by default. No configuration needed. Just click Run or Build. It will run in parallel.
If you want to see this, other than seeing your project build faster, check Task Manager. You should see a bcc64x process with approximately twice as many threads as the number of cores on your machine, and approaching 100% CPU usage.
Docs are available: this uses the –jobs parameter and batch compilation. Setting ‘Number of subprocesses’ to 0, which is the default, sets the number of parallel compiles that can happen at once, where 0 means to use as many as it can (about 2x your core count.)
We recommend not touching the default settings at all since it works to build as fast as it can out of the box.
If you need to check the settings, such as if you are not sure, or if you don’t see a performance boost (you will notice!), here’s what to make sure they’re set to:

- Make sure you have the Windows 64-bit Modern platform selected and active in your project.
- Go to Project Options. Make sure you select ‘All Configurations’ in the dropdown.
- Building > C++ Compiler > Enable Batch Compilation should be set to true. Double-check that none of the other target configurations override it; this should be the default set at a high inherited level.
- Project Properties > General > Number of subprocesses should be set to 0. This uses every core you have.
CI and DevOps builds / build servers
If you are building your app on a build server, you are either using CMake or most likely are building using msbuild on the command line, something like ‘msbuild MyProject.cbproj’ possibly specifying a target.
If so, you’ll find that when your .cbproj file is set to build with the new toolchain, it builds using as many cores as it can by default. You don’t need to change settings.
If you are invoking bcc64x.exe manually, such as a build script written manually, ensure you have 12.2 Patch 1 installed. This enabled the feature outside the IDE on the command line via the –jobs parameter. Invoke the command line as:
|
1 |
> bcc64x a.cpp b.cpp c.cpp --jobs=0 ...other parameters |
This “batches” (sends all C++ files at once) and invokes jobs (the parallel building) with 0 meaning ‘all cores’.
Efficiency
This uses a new implementation of –jobs, and is much more efficient than the older version. Our internal testing show that the internal compiler batching and handling of parallel processing is also more efficient than using ninja or other common build tools.
However, that efficiency in design is good but the actual compilation is where the vast amount of CPU usage goes.
We recommend giving the new C++Builder as many cores and as much RAM as possible.
If you can give it a 20-core machine, and 64GB of RAM, do it. If you can give it more cores than that, do it. The more cores the better. The more RAM the better.
Tip: keep an eye on bcc64x.exe memory usage as you build. It will use every core you give it. Some complex C++ code can use a lot of memory per file, which can add up: 20 files using 1GB each is 20GB of RAM: if a couple of individual files balloon to 3GB each you’re at 26GB of RAM for one segment of the build. So you want to avoid causing it to swap to disk when it needs to use more memory than is available.
This behaviour depends very much on your own code, so you need to run a build and see what it does on your source, ie, whether your source requires more RAM to build. While you could limit the number of cores it uses via the ‘number of subprocesses’ setting, we recommend instead in this situation to give it more RAM.
Run it on your code, watch its behaviour, and adjust your server or build machine as necessary.
The new system also scales with the number of files you’re compiling. There are overheads, and those shrink the more C++ code you give it. So it very genuinely is more efficient to compile 100 files than 10 files. This means it’s great for massive apps. (Don’t forget the new linker is also much faster, and can handle massive linksets / apps too.)
Real World Results
The above webinar launch slide was with synthetically generated code (5000 files and 360,000 lines of code.) In real world apps, performance varies compared to this. We found that especially with code that was complex and heavily used the STL, performance got far closer to other indsutry standard solutions.
So what can you expect to see with a real app?
We recently gave a webinar on the new C++Builder, and showed the real-world result for a small demo app. This uses the STL, so is an example of code that may not perform as well as in the chart above. Plus, this project is the least efficient case possible — yet still shows a massive improvement.
Why is it the least efficient case possible? Because the demo app has only six C++ files, and is running on a mere 4-core machine. That means it’s going to compile in parallel and be unable to saturate CPU for more than a few seconds (think of it as batching 4 files, then batching the remaining 2, but over 4 cores so only being able to use half the computer’s resources), plus the overheads around building are more visible for such a small amount of code.
So this is a great illustration of overheads and how efficiency works.
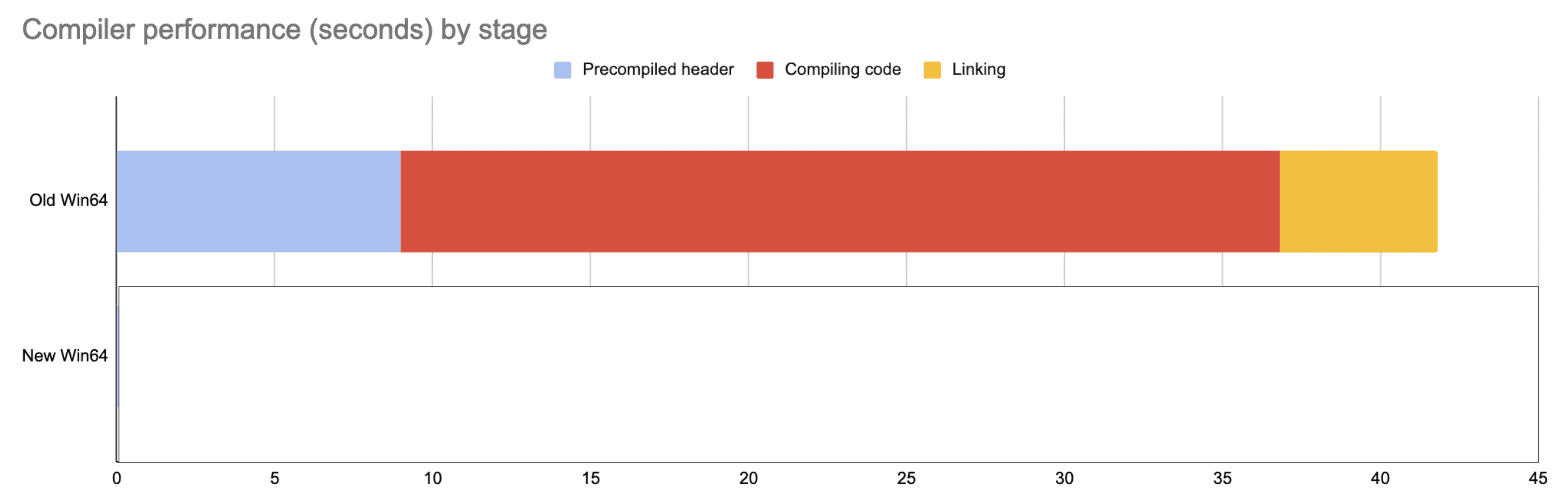
Here’s a chart of building this app using the old and new systems.
At the top is how it used to work, building the old way in serial, one file after another. First, it generates a precompiled header: this took 9 seconds using a single core. Then, it compiled all six files one after the other, taking 27.8 seconds; then it linked, taking 5 seconds.
(On the left in blue, the overhead of the precompiled header; in red, compiling the code; in yellow, linking.)
 But the bottom chart, where smaller is better, shows the new system that’s on by default.
But the bottom chart, where smaller is better, shows the new system that’s on by default.
It still needs to build the precompiled header (blue). This takes ten seconds, single core, and needs to be done before the parallelization can begin. This is overhead, and the relative time this takes will shrink the more time you spend actually compiling.
However, it then jumps right into building in parallel (red), and the total compile time is 5.8 seconds. (That’s a 4.8x speedup on my 4-core VM, and is going from 27.8 seconds to 5.8 seconds!)
Then it links (yellow): this takes 1 second. This too is overhead, but note that the new linker is much faster, five times faster here!
So you can see what we mean: it will saturate your CPU, and the more files you give it, the more efficient, because it will saturate your CPU for longer and the relative overhead of other build parts will shrink.
Compared to classic
A common question from those still using the old legacy Classic Win32 compiler is: how do I get it as fast as classic? And classic, which hasn’t been updated since the end of the 2000s, is faster – but does a lot less. Clang does a lot more, but takes more time, and for those asking this question, the balance of time vs features (eg optimisation, language support, libraries etc) is tipped in the favour of time.
Our own tests tend to show it approaches classic when you give it enough cores. While any hard number depends on your code, one test I did for one codebase showed that at about 10-12 cores it was as fast as classic. It may be more, or less, depending on your own code.
Our recommendation above is to give it as many cores as you can. It seems reasonable to say that with enough cores you’ll get faster than classic.
If you are using classic, we strongly recommend upgrading. The Win64 toolchain is the future – but here now.
Results!
We hope this information has been useful. Since it’s on by default with the right settings, you should see this simply by installing 12.2 (or newer), and ensuring you’re using the Modern Win64 toolchain. (This is not supported for the old one.) Very likely in future the Modern Win64 toolchain will be the only Win64 toolchain.
We hope this is a great performance boost (‘just install the update, use the platform, and it happens without configuring settings’ is pretty cool, we think), and especially encourage you to look at it if you’re using the old classic compiler.
Remember: more cores!



Reduce development time and get to market faster with RAD Studio, Delphi, or C++Builder.
Design. Code. Compile. Deploy.
Free Delphi Community Edition Free C++Builder Community Edition



{kind=link}
Does this obsolete TwineCompile, leverage it, or neither?
TwineCompile is a valuable product and partner, and is really useful for other compilers especially. For bcc64x, consider the two as the same goal, though where this one is now on by default and the supported solution (it is just how projects are compiled now.)
Our implementation leverages that we have access to the compiler source so we do things TC can’t, which is really around the efficiency of overheads per compile. Those are small compared to the actual compile work though.
For me msbuild on command line is very slow -> see https://embt.atlassian.net/servicedesk/customer/portal/1/RSS-3803